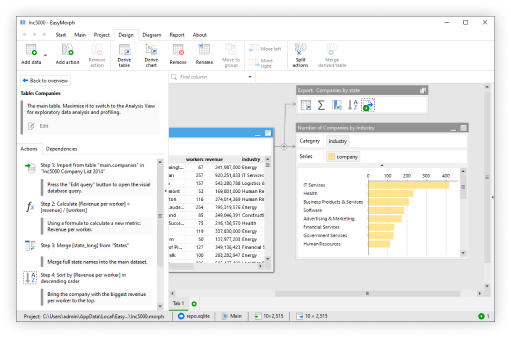
The "Big Data" hype that dominated the IT industry for over 15 years is over and has been replaced by the next hype. Google Trends shows that the number of searches related to “Big Data” steadily declines, falling almost twice from its peak a few years ago.
The main premise behind the "Big Data" hype was the idea of "data explosion". We've been told that the volume of data now grows exponentially at such a pace that you absolutely, definitely, undoubtedly need Big Data because if you don’t have it, all the terrible business horrors that can happen to your organization will definitely happen: your customers will switch to competitors (who, of course, bought all the most loudly praised Big Data systems), your business systems will fall apart (because they can’t handle the inevitable Big Data), and your understanding of your own business will evaporate (because without Big Data you’re blind).
But did the data explosion actually happen?
For some, yes, but for many, it didn’t. Even in those organizations that have experienced a dramatic growth of accumulated data, the Big Data technology stack still has limited use, because most people (especially in business departments) work with aggregated data, which is usually far less in volume and can be handled without the inconvenience and compromises typical for the Big Data stack (I’ll elaborate on that below).
For the rest of the organizations, the data explosion simply has nowhere to come from. Besides that, there are many forces working against a data explosion.
Fact tables
Let's look at what is known as a fact table. Fact tables typically are at the core of any business automation application. In a fact table, the rows represent transactions or events that occurred in the course of a business process, and the columns represent the attributes of these transactions (events). To keep things simple, we can assume that the amount of data in a fact table is simply the number of rows multiplied by the number of columns. For those familiar with the big-O notation, it’s O(events * attributes).

So, where would the data explosion for fact tables come from? Would it come from the explosive growth of transactions? For most businesses, the number of transactions doesn't grow exponentially. Grocery stores didn't start selling exponentially more products. People didn't start making exponentially more phone calls. Airlines didn't start flying exponentially more people. Ultimately, the gross domestic product (GDP) didn't start growing explosively. I wouldn’t be terribly off if I assume that the number of commercial transactions grows slowly every year, in line with GDP growth.
Okay, so if the number of transactions doesn't grow exponentially in most businesses, maybe the number of attributes for each transaction (and therefore the number of columns in fact tables) has exploded instead. I doubt so as well. The number of fields in an average invoice hasn't changed much over the last 50 years - invoice number, date, customer name, address, due date, total amount, and similar fields can be found in invoices created today or those created 30 years ago. The same is true for your grocery bill - there isn't much added to it. The vast majority of businesses operate pretty much the same set of event/transaction attributes as they did 10 or 20 years ago, because these attributes are defined by the nature of their business more than anything else. Yes, it has probably grown as data models tend to bloat when the organization becomes older, but that's hardly explosive.
So common sense tells us that the number of transaction attributes doesn't grow exponentially either. Thus, fact tables don't grow explosively.
Saturation of business automation apps
Okay, maybe fact tables don't grow exponentially themselves, but maybe the number of fact tables themselves is exploding instead? Fact tables typically represent events happening over the course of a business process. Indeed, the more business processes are automated, the more events are recorded, and the more data is collected in business applications. It's true that organizations use increasingly more business applications, especially as a result of the SaaS proliferation. A large bank can use as many as 800 business applications - all of them capturing various events, transactions, and their attributes. That's a lot! Would it grow exponentially further? It will definitely grow - there is still room for automation in most organizations. But will it grow exponentially and explosively? I don't think so. The massive shift to business automation began in the 1970s, over 50 years ago. By now, organizations, on average, already demonstrate a pretty high degree of business automation. Of course, everyone working in enterprise IT has a favorite story about a silly manual process in their organization, but they are funny exceptions in most cases.
Data is a liability
Another reason why the data explosion is so limited in scale is that data is not only an asset, but is also a liability. More than that, unnecessary, or low-quality, or low-utility data is way more of a liability than an asset. Its value is net negative because any value I may be able to derive from it is dwarfed by the cost of keeping it.
Data needs to be stored, backed up, indexed, and documented. If data contains personal or sensitive information, then it falls under many legal regulations, such as HIPAA or GDPR, that make storing and processing it even more difficult and expensive. In many cases, regulations demand deleting data after a period of time, which also works against data volume growth.
Data needs to be protected. Access to data needs to be managed. The more data you have, the more effort is required to protect it.
Unnecessary data is a drag on productivity. The more low-utility data you have to sift through, the harder to find what you need - the bigger the haystack, the harder it is to find the needle. As you can see, there are plenty of "anti-explosion" forces that work against data growth and keep data volumes in check. For many, "Data explosion" didn't actually happen because it would also mean an explosion in costs and burden, and, unsurprisingly, that doesn't look attractive to many.
Most people don’t work with Big Data
Jordan Tigani, the co-founder of DuckDB and an ex-Googler who worked on BigQuery, writes in his excellent essay "Big Data is dead":
When I worked at BigQuery, I spent a lot of time looking at customer sizing. The actual data here is very sensitive, so I can’t share any numbers directly. However, I can say that the vast majority of customers had less than a terabyte of data in total data storage. There were, of course, customers with huge amounts of data, but most organizations, even some fairly large enterprises, had moderate data sizes.
Even if your organization has massive volumes of data and you use Big Data technology to handle it, most of your colleagues (especially outside of the IT department) probably work with aggregated derivatives from that data and operate with much smaller volumes of data.
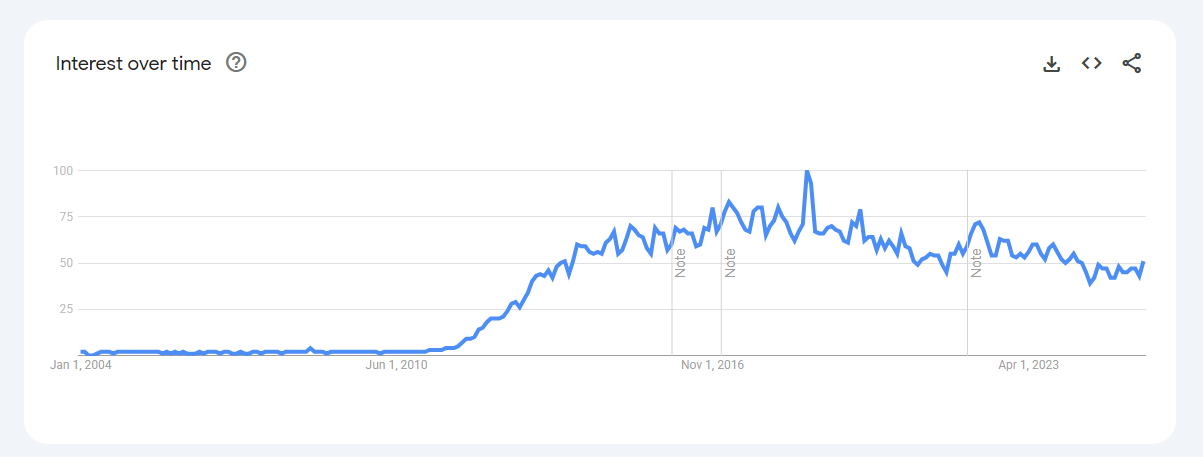
In my survey published on LinkedIn a year ago, 97% of respondents reported that they usually work with datasets that have fewer than 100 million rows. While the audience may not be statistically significant, it nevertheless supports Jordan Tigani’s observation that most people who work with data do not work with large volumes of data.
Big Data technology is a poor choice if you don’t need it
Okay, but the Big Data tools are still great, aren’t they? Well, any Big Data technology is full of compromises necessitated by the large volume of data it needs to handle. These compromises are usually dictated by the inability to handle all data within a single computer and the impracticality of moving large datasets. Computer hardware, despite constant advances, has physical limitations in terms of memory and computing power. Alas, with the current computer technology, it’s not possible to create a single computer that can hold and process whatever volume of data an organization requires. As a result, beyond a certain volume, data must be distributed across multiple computers for storage and processing. In other words, any Big Data technology is based on distributed computing, and distributed computing is a well-known hard problem in computer science. It has several unavoidable limits (see, for instance, the CAP theorem) not present in non-distributed systems. Accessing, updating, aggregating, and analyzing distributed data is hard, slow, and inconvenient. That’s why Big Data tools are clunky, cumbersome, and expensive - because they are designed to solve the hard problems of distributed computing.
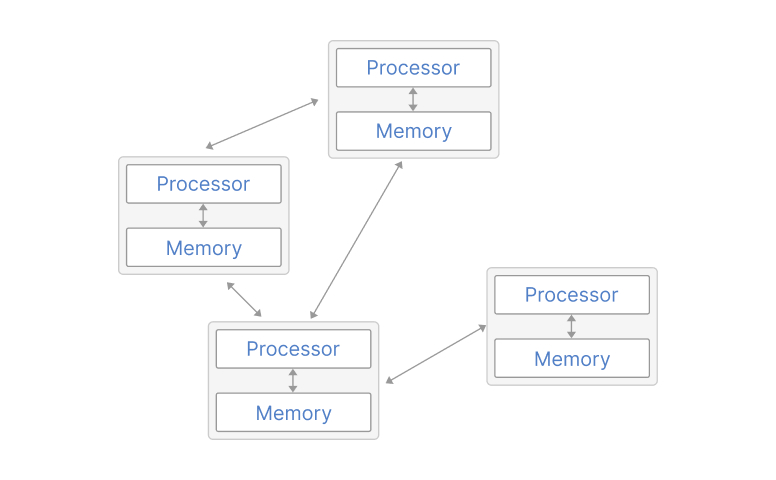
Another limitation that is pertinent to Big Data is that moving it isn’t practical. Copying or moving a large volume of data from one location to another is slow and expensive. That’s why the Big Data stack is built around the premise that you can only process data where it’s stored, which further restricts the range of options for how data can be processed.
The silent rise of "medium data"
Most compromises and inefficiencies typical for Big Data are not necessary when the data volume is sufficient to fit into one computer’s memory or can be processed with one computer in a reasonable time.
Not having to deal with distributed data and computing removes many problems and enables:
- Fast data processing, frequently entirely in-memory, without slow disk or network I/O
- Great data insight, as datasets can be viewed and analyzed in their entirety instantly or almost instantaneously
- Low costs and easy software administration as no distributed computing is required
I call such cases "medium data". "Medium data" systems tend to be easy to use, fast, and inexpensive. No wonder they are typically highly acclaimed by users, as they offer a great user experience and autonomy, not possible with Big Data tools.
Shadowed by the Big Data hype, "medium data" has silently proliferated thanks to incremental steady advances in computer hardware. While data volumes didn’t explode in many organizations (for reasons I explained above), computer specs kept adhering to Moore’s Law and grew exponentially, allowing more and more data to be processed on a single computer, frequently entirely in memory. For instance, in 2010, when the term "Big Data" skyrocketed in search queries, a decent server had 16GB of RAM. Nowadays, servers with 128 or 256GB of RAM (an increase by an order of magnitude) are considered regular, while higher-end machines can have 1TB of RAM or more.
Ironically, the data volumes that were classified as "Big Data" at the beginning of the Big Data hype are now handled by "medium data" systems with greater ease and convenience. Datasets with 50 or 100 million rows were considered Big Data just a decade ago, but that’s no longer true. Now, they can be transformed on a desktop computer in seconds, using inexpensive software.
And with ease and convenience comes better work productivity.
What are "medium data" apps
Those who don’t need the Big Data tools are lucky because they can benefit from "medium data" software free of the compromises and limitations dictated by Big Data. You can manipulate data easier, build data pipelines faster, and understand your business better. And did I mention that you are spared from big Big Data bills as well?
All "medium data" apps have two distinct features:
- They are designed in such a way that makes them scale vertically, as computer hardware specs keep growing. In other words, they piggyback on Moore’s Law.
- They process data locally, on one computer.
A few examples of applications that offer outstanding ease of use and performance by targeting "medium data":
EasyMorph
When I started EasyMorph, I wanted to create an easy-to-use data preparation tool for non-technical people. However, the "medium data" engine that lies at the heart of EasyMorph turned out to be significantly more capable than initially envisioned. As of today, EasyMorph has evolved into a versatile data engineering platform for "medium data", used by data engineers and data analysts with varying degrees of technical expertise.
From a technical standpoint, EasyMorph processes all data locally, in memory, using advanced data compression algorithms. Because of that, it’s fast, offers excellent insight into data, and makes you focus more on delivering business value rather than fighting technology and wasting your time unproductively.
Qlik
One of the “medium data” pioneers in data and analytics. Their dashboarding application, initially known as QlikView, employs a fast in-memory engine backed by powerful ETL scripting. The company was quick to embrace the shift to 64-bit general computing and the drastic decrease in computer memory prices. QlikView quickly gained popularity due to its ease of use, performance, and versatility.
Unfortunately, despite technical brilliance, the company has made a few strategic product mistakes when releasing Qlik Sense, the successor of QlikView. These mistakes set it back and let competitors, such as Tableau, leap ahead. Nevertheless, Qlik Sense is still a viable alternative to popular Business Intelligence applications.
DuckDB
A recent entrant in the “medium data” market that is rapidly gaining popularity. DuckDB was founded by ex-Google engineers who developed BigQuery. DuckDB is a local serverless database intended for analytical workloads. It’s fast, easy to administer, offers a great variety of connectors, and works well for custom-built analytical applications.
Some popular data tools lack these features and thus don’t qualify as "medium data" apps:
- Excel - doesn’t scale up with hardware, has low data limits, and its performance strongly degrades when approaching the limits
- MS Access - doesn’t scale up with hardware too, forever limited to 2GB per database
Where does it leave us?
The limited blast radius of the "data explosion" is actually good news.
Most people working with data today still operate with "medium data" - an amount of data that can actually fit on one computer or can be processed by one computer. This fact makes working with "medium data" much easier and more comfortable than using cumbersome "Big Data tools" because working with local data eliminates whole layers of problems that are unavoidable otherwise. Tools like EasyMorph are designed specifically for "medium data" and employ local in-memory data processing that offers numerous advantages - data visibility, speed, and ease-of-use that result in higher work productivity, lower costs, and better developer experience overall.
Don't take my word for it! Download the free edition of EasyMorph today, give it a try, and see the convenience of local in-memory processing yourself. Seeing is believing.